Es sin dudas un evento histórico. En Estados Unidos la FDA (Agencia Federal de Alimentos y Medicamentos) lanzó hace unos meses su plataforma OpenFDA, un catálogo de datos abiertos para que desarrolladores, investigadores y el público en general pueda tener acceso a una gran y muy importante cantidad de conjuntos de datos de salud recolectados por la agencia.
La acción se alinea con la orden ejecutiva que el Presidente Obama firmó para promover el desarrollo de los datos abiertos en toda la administración pública norteamericana. La plataforma utiliza una API (Application Program Interface) para recolectar grandes cantidades de datos disponibles, ofreciendo a desarrolladores la habilidad de buscar más eficientemente entre millones de registros.

¿Qué hay en el dataset?
La plataforma todavía está en BETA y en esta primera fase la FDA puso a disposición millones de reportes sobre efectos adversos causados por medicamentos como así también errores en la medicación informados al FDA entre el 2004 y el 2013. Previo a este nuevo formato, la información sólo se conseguía a través de un complejo sistema de resportes vía pedidos de acceso a la información.
Cada uno de los reportes disponibles no contienen ningún tipo de información que pueda potencialmente ser usada para identificar individuos u otros datos privados. El piloto será ampliado para incluir las bases de datos del FDA sobre productos retirados o problemas con el etiquetado.
“A través de esta novedosa organización de lo datos, estos reportes están disponibles completos para que desarrolladores de software pueda construir herramientas que puedan ayudarnos a descubrir información clave y acercarla más rápidamente a consumidores y profesionales de la salud”, dijo el Dr. Taha Kass-Hout, director de Informática del FDA.
La API nos permite acceder a una lista de eventos ocurridos por efectos adversos causados por medicación en Estados Unidos desde el 2004. Un efecto adverso es informado al FDA ante experiencias indeseables asociadas con el uso de un medicamento, incluyendo serios efectos secundarios, errores en el uso de un producto, problemas de calidad, y fallas terapeúticas.
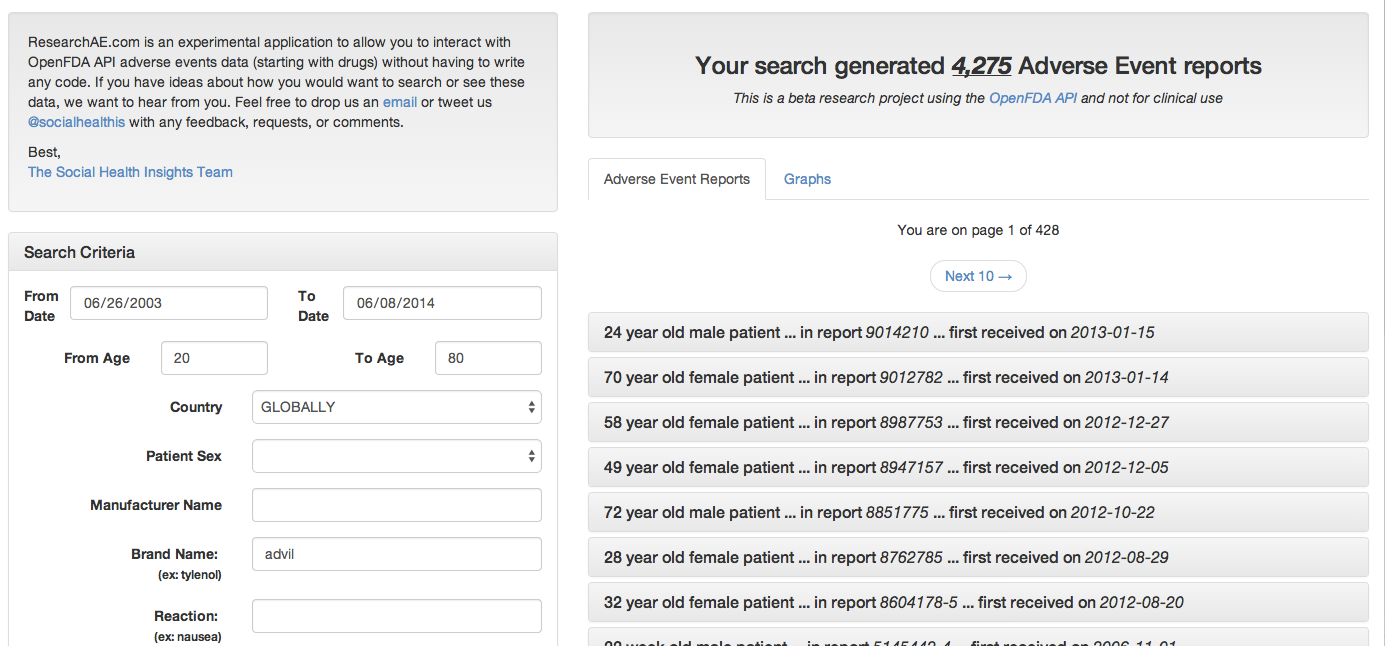
Las primeras aplicaciones construidas para navegar los datos ya empiezan a aparecer. Researchae, desarrollado por SocialHealth, se presenta como “un experimento para interactuar con los datos del FDA sin tener que escribir ni una línea de código”. A través de un formulario podemos por ejemplo preguntar por todos los casos de efectos adversos causados por X medicamente, filtrar por fecha, edad o bien tipo de reacción.
¿Qué nuevas aplicaciones surgirán a partir de estos datos? ¿Cómo serán los trabajos prácticos en universidades, las visualizaciones, los análisis sobre información tan valiosa? ¿Qué impacto tendrá en el mercado y en los consumidores?